
Top 200 Highest-Grossing Movies of All Time
How to collect highest-grossing movies in your movie list using BeautifulSoup
Introduction
I am a super movie fan and I believe you are as well. Aren’t you curious about what movies are on the Top 200 Highest-Grossing Movies of All Time list? I am curious! Moreover, high-grossing movies often means high rating and are mostly good movies. I am excited to put some more great movies in my pocket list.
The dataset I use is form IMDb website. They list the details of each movie in the list like ranking, title, year, runtime, rating, box office, and etc.
This is what the Highest-Grossing Movies of All Time list looks like on their website:
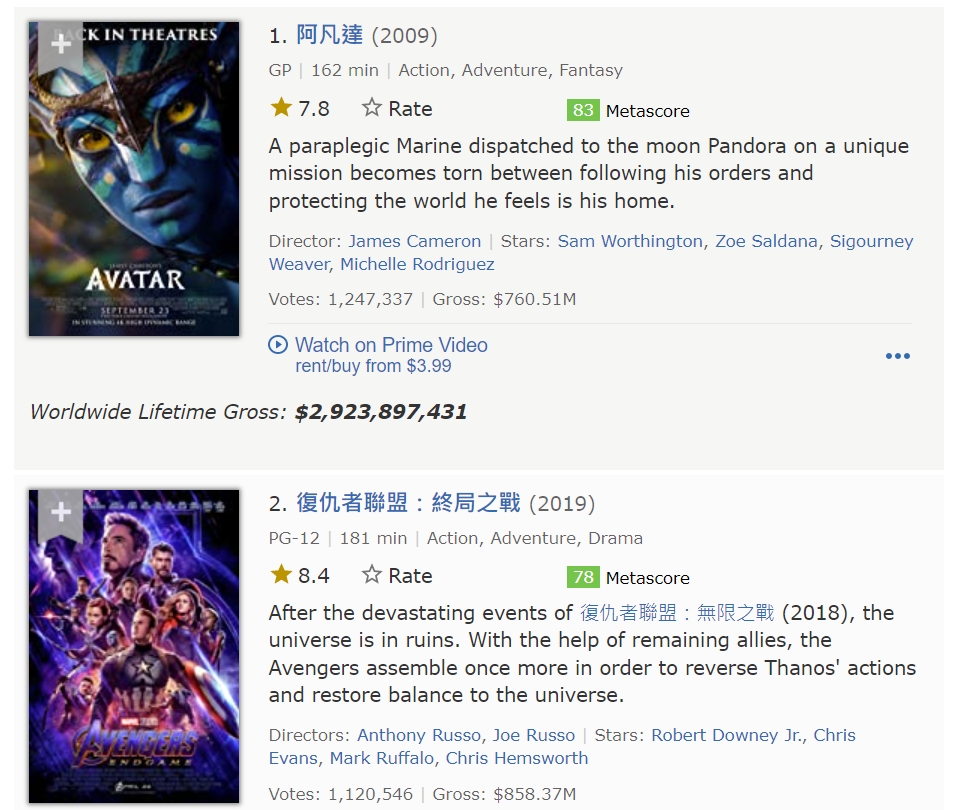
Our goal is to get the six variable we want which are ranking, title, year, runtime, rating, and box office for the top 200 movies using BeautifulSoup. Then we put together all the data we got as a dataframe/table.
Check the website’s status code
The first thing we should do is check the status code to see if the website allow us to get data from them.
To do that, you can use requests.get(your_url).status_code to get the code. The code we got is 200, we are good to go :)
Get the HTML code and we are in business.
Here we finally use a BeautifulSoup function. We use BeautifulSoup(your_url.text) to get the html code we want. And this where all the funs begin!
This is the step we scrap all the interesting data
Looking at the html code, we found the desired data are all in a class called lister-item-content
We scraped all the columns we want using codes below:
gross_divs = w_soup.find_all('div', {"class":"lister-item-content"})
All the tables are in lister-item-content classrank = [int(h.find('span', {"class": "lister-item-index unbold text-primary"}).text.strip('.')) for h in gross_divs]
All the rankings are in lister-item-index unbold text-primary classtitle = [h.find('a').get_text() for h in gross_divs]
Titles are easily found in a hrefyear = [h.find('span', {"class": "lister-item-year text-muted unbold"}).get_text() for h in gross_divs]
All the years are in lister-item-year text-muted unbold classrating = [(h.find('span', {"class": "ipl-rating-star__rating"}).get_text()) for h in gross_divs]
All the IMDb ratings are in ipl-rating-star__rating classruntime = [int(h.find('span', {"class": "runtime"}).text.strip(' min')) for h in gross_divs]
We usetext.strip()to get rid the “min” in runtimegross = [(h.find_all('span', {"name": "nv"}))[-1].get_text() for h in gross_divs]
Usefind_all()to find votes and gross, and get rid of votes by adding [-1]
</ul>
Create Dataframe Using Pandas
Make sure you have pandas imported, and then create a dataframe by saying pf = pd.DataFrame()
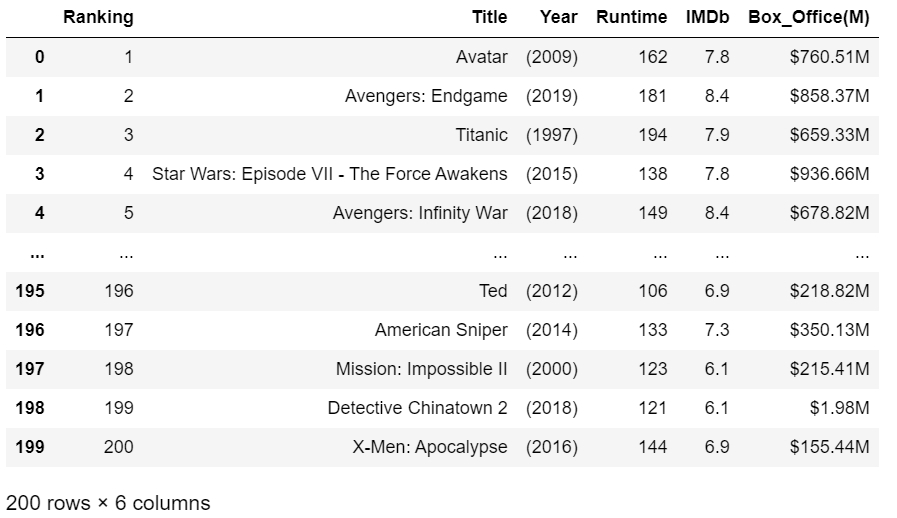
Then combine two dataframes into one.
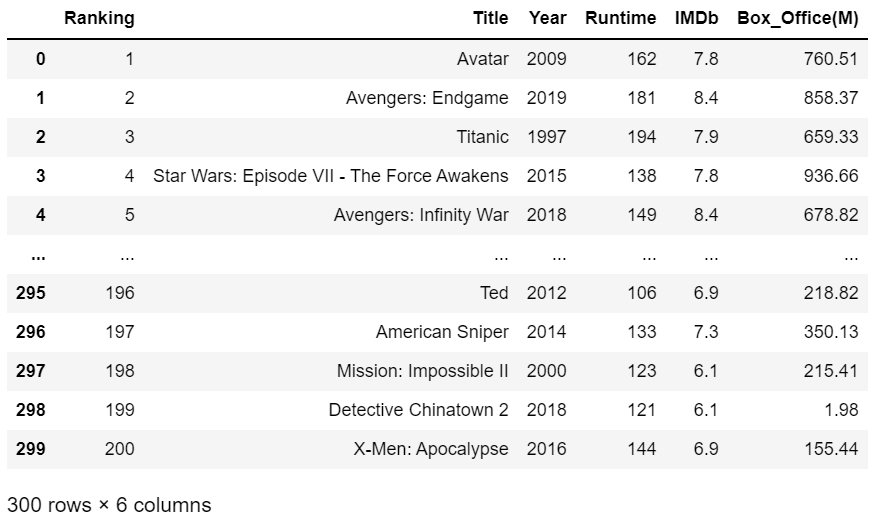
Final data cleaning
Since the column df[Year] and df[Box_Office(M)] still contain (), $, and M. We need to do some cleaning.
df['Year'] = df['Year'].str.extract(r'(\d\d\d\d)').astype(int)
We usestr.extract()to get rid of the ()df['Box_Office(M)'] = df['Box_Office(M)'].str.partition('$')[2].str.partition('M')[0]
The firststr.partition()eliminate $, the second eliminate M
</ul>
The resulting dataframe will look something like this:
Is this ethical?
Yes, this is completely ethical since the IMDb website allows people to web-scrape their website as the status code shows. I also did not use it for commercial purpose, this is for my personal use to add more movies to my list.
Conclusion
In this post, I show you step-by-step from how to check the status code, scrap the variables you like, put together as a table, and finally make the dataset clean and looking-good using BeautifulSoup. This post is extremely useful to those who needs to collect, wrangling, and analyze online data for personal use. I will also an exploratory data analysis (EDA) of this dataframe on my next post, hope you enjoy this post and look forward to the next one.
Here’s a link to my github repo link